
Tester’s role in the project is often seen in two major areas: building confidence in that software fulfill its need and on the other hand finding parts where it does not, or might not. Just pointing finger where the problem lies is seldom enough: the tester needs to tell how the problem was encountered and why the found behavior is a problem. The same thing goes with enhancements ideas. This post is about how to work with bugs ( what we call defects in this post ) and other findings ( we call all the findings issues ) from writing those to closing them.
Using time wisely

While small scale projects can cope with findings written on post-it notes, excel sheets or such, efficient handling of large amounts of issues is next to impossible. The real reason for having a more refined way of working with issues is to enable the project to be able to react to findings as needed. Some issues need a fast response, some are best listed for future development, but not forgotten. When you work right with issues, people in the project find the right ones to work with a given time, and also understand what the issue was written about.
As software projects are complex entities, it is hard to archive such thing as perfect defect description, but they need to be pretty darn good to be helpful. If a tester writes a report that the receiver does not understand, it will be sent back or even worse – disregarded. That said, getting the best bang for the buck for tester’s time writing the defect is not always writing an essay. If the tester sits next to the developer, just a descriptive name for the issue might be enough. Then tester just must remember what meant by the description! The same kind of logic goes with defect workflows. On some projects, the workflows are not needed to guide the work, but on some, it really makes sense for an issue to go through a certain flow. There is not a single truth. This article tells some of the things you should consider. You pick what you need.
Describing the finding
The first thing after finding a defect is not always trying to write it down to an error management system as fast as possible. Has the thing been reported earlier? If not, the next thing is to find out more about what happened. Can you replicate the behavior? Does the same thing happen elsewhere in the system under test? What was the actual cause of the issue? If you did a long and complex operation during the testing, but you can replicate the issue with a more compact set of actions, you should describe the more compact one.
After you have an understanding of the issue, you should write ( a pretty darn good ) description of the issue. The minimum is to write the steps that you did. If you found out more about the behavior, like how in similar conditions it does not happen, write that down too. If the issue can be found executing the test case, do not rely on that reader would read the test case description. Write down what is relevant to causing the issue. Attached pictures are often a great way of showing what went wrong, and attached videos a great way of showing what you did to cause that. They are really fast to record and a good video shows exactly what needs to be shown. Use them.
Consider adding an exact timestamp you tested the issue. The developers might want to dig into the log files – or even better, attach the log files yourself. It is not always clear if something is a defect. If there is any room for debate, write it also down why you think the behavior is a defect.
Besides writing a good description, you should also classify your defects. This helps the people in the project to find the most important ones for them from the defect mass. Consider the following:
| Field | Motive |
| Priority | Not all issues are as important at the moment. |
| Severity | Severity tells about the effect of the issue. That can be different than the priority. Then again, as in most projects, severity and priority go hand in hand. Then it is just easier to use just one field. |
| Assignment | Who is expected to take the next step in handling the issue? |
| Type | Is the issue a defect, enhancement idea, task or something else. |
| Version detected | What version was tested when the issue was found. |
| Environment | In what environment was the issue found. |
| Application area | To what application area issue has an effect. |
| Resolution | For closed issues, the reason why the defect was closed. |
Add the fields to your project that are meaningful for you to classify defects and hide the ones that are not relevant. If you are not sure if you benefit from the classification field, do not use the field. Use tags. You can add any tags to issues and find the issues later or report them. Easy.
Issue wrote – what next?
Now that you wrote an error report, did you find it by conducting an existing test? If not, should there be a test that would find that given defect? After the issue has been corrected you probably get to verify the fix, but if the issue seems likely to re-emerge, write a test case for it.
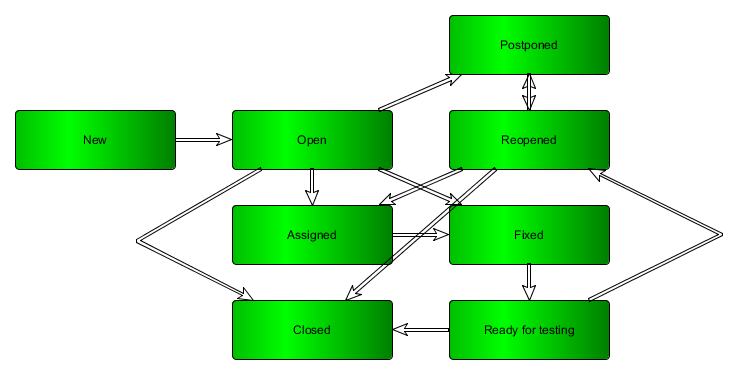
Writing an issue begins its life cycle. At the bare minimum, the defect has two stages – open when you work with it and closed when you have done what you wanted to do, but most of the time the project benefits from having more stages in the workflow. Mainly the benefits come from easier management of large amounts of findings. It helps to know what needs to be done next, and by whom. Having information in what state the issues are, the project will be able to distinguish bottlenecks easier. Generally the bigger the project, the more benefits there are to be gotten from having more statuses. That said, if the statuses do not give you more relevant information about the project, do not collect them. Simpler is better.
| Status | Motive |
| New | Sometimes it makes sense to verify the issues before adding them to further handling by someone else than the initial reporter. New distinguishes these from Open issues. |
| Open | Defects that have been found, but no decision on how the situation will be fixed have been made yet. |
| Assigned | The defect is assigned to be fixed. |
| Reopened | Delivered fix did not correct the problem or the problem occurred again later. Sometimes it makes sense to distinguish the opens from reopened to see how common it is for problems to re-emerge. |
| Fixed | Issues are marked fixed when the mentioned issue has been corrected. |
| Ready for testing | After the issue has been fixed this status can be used to mark ones that are ready for testing. |
| Postponed | Distinguish those open issues that you are not planning to work with for a while. |
| Closed | After the findings have been confirmed to cease to be relevant, the issue can be closed. Basically after fixing the issue will be tested. |
When working with defects and changing their statuses, it is important to comment on the issues when something relevant changes. Basically, if the comment adds information about the found issue, it probably should be added. The main idea behind this is that it is later possible to come back to the discussion so you don’t need to guess why something was done or wasn’t done about the issue. Especially it is important to write down how the change will be fixed (when there is room for doubt), and finally how the fix has been implemented so that the tester will know how to re-test the issue. If the developer can open the way how the issue was fixed it helps tester find possible other issues that have arisen when the fix has been applied.
Digging in the defect mass
So now that you have implemented this kind of classification for working around issues, what could you learn from statistics? First off, even with sophisticated rating and categorization, the real situation can easily hide behind numbers. It is more important to react to each individual issue correctly than to rate and categorize issues and only later react to statistics. That said, in complex projects, the statistics, or numbers, help understand what is going on in the project and help find the focus on what should be done on the project.
The two most important ways to categorize defects are priority and status. Thus a report showing open issues per priority, grouped by status is a very good starting point to look at the current issue situation. Most of the time you handle defects differently from other issues, so you would pick the defects to one report and other types of defects to others. Now, this kind of report might show you for example that there is one critical defect assigned, 3 high priority defects open and 10 normal priority defects fixed. The critical and high priority defects you would probably want to go through individually to make at least sure that they get fixed as soon as they should so they do not hinder other activities, and for the fixed ones you would look if something needs to be done to have them enabled for re-testing. If at some point you see some category growing, you know who should you ask questions. For example, a high number in assigned defects would indicate a bottleneck in development and prolonged numbers in “ready for testing” a bottleneck in testing.
Another generally easy to use report is the trend report for open issues by their statuses or issues’ development. As the report shows how many open issues there has been at a given time, you’ll see the trend – if you can close the issues the same pace you open them.
This was just a mild scratch in the area of working with defects. If you have questions or would like to point out something, feel free to comment.
Happy hunting!
Joonas